




FERTIG INSTALLIERT MIT READY-TO-BRAIN™ TECHNOLOGIE
Die Installation und Einrichtung leistungsfähiger KI- und GPU-Systeme ist komplex, zeitaufwendig und häufig von Trial-and-Error geprägt. Statt wertvolle Arbeitszeit mit Linux-Installationen, Treibern und Software-Stacks zu verbringen, sollten Sie sich auf das konzentrieren, was zählt: Ihre KI-Workloads.
Mit der Ready-to-Brain™ Technologie von CADnetwork® sind unsere AI-GPU-Systeme sofort einsatzbereit. Alle Server werden vollständig vorkonfiguriert und mit einem abgestimmten Software-Stack für moderne KI-Anwendungen ausgeliefert.
So können Sie ohne Vorlaufzeit direkt mit Training, Inferenz und Entwicklung beginnen – zuverlässig, reproduzierbar und professionell.
KOMPATIBEL MIT VIELEN KI FRAMEWORKS
Unsere GPU-Systeme für KI-Workloads sind mit allen gängigen KI-Frameworks kompatibel. Bereits vorinstalliert sind unter anderem TensorFlow und PyTorch. Darüber hinaus können jederzeit eigene Frameworks, Bibliotheken oder Versionen ergänzt und genutzt werden. Dank der integrierten Docker-Umgebung lassen sich KI-Frameworks und Workloads flexibel als Container bereitstellen. So können unterschiedliche Projekte, Versionen oder Teams sauber voneinander getrennt betrieben werden – reproduzierbar, wartbar und ohne Eingriffe in das Basissystem.
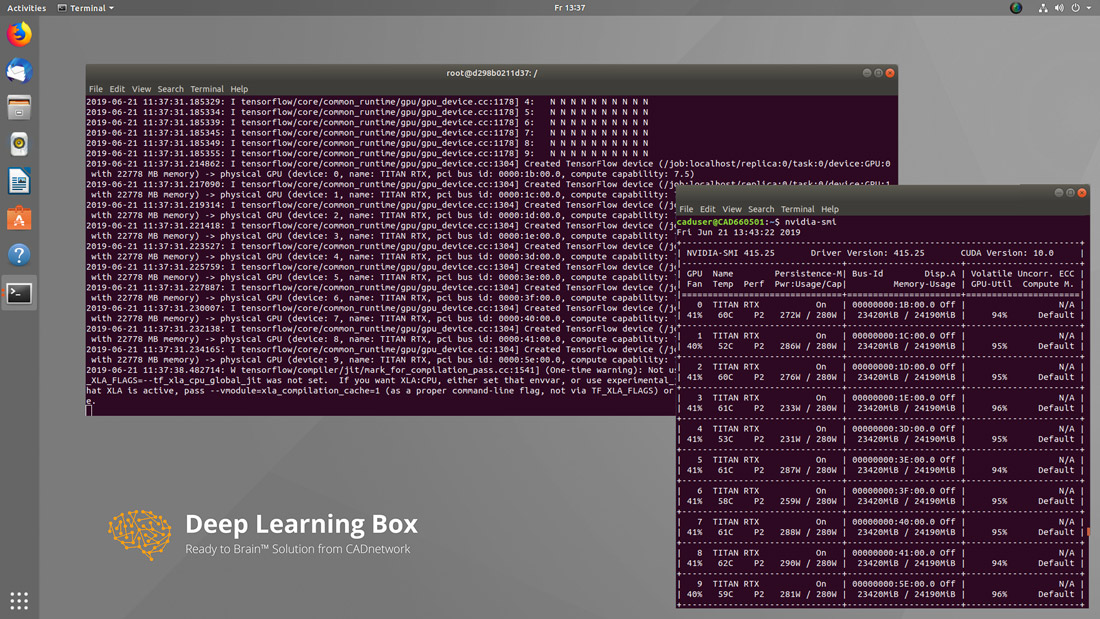
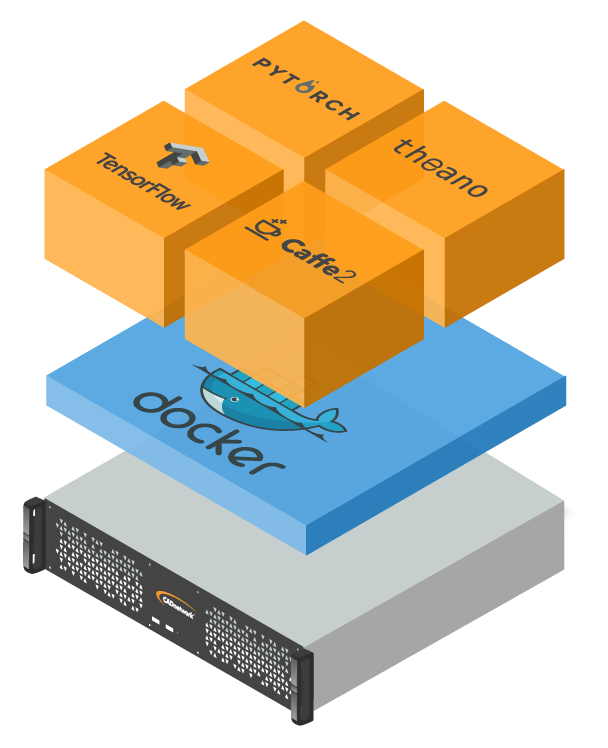
MIT UMFANGREICHEM DL SOFTWARESTACK
Die CADnetwork® Deep Learning Box ist mit einem umfangreichen Softwarestack für AI Anwendungen ausgestattet. Die Deep Learning Frameworks und Bibliotheken sind hierbei in komfortablen docker Containern angeordnet und ermöglichen so einfachen und stabilen Zugriff auf die Ressourcen. Die gängigsten Frameworks wie z.B. TensorFlow und PyTorch sind bereits fertig installiert und sofort einsatzbereit